Analyse Technique Approfondie
Pile Vision Par Ordinateur
Librairies Principales
| Composant | Version | Rôle |
|---|---|---|
| PyTorch | 2.9.0 (CUDA 12.6) | Framework de Deep Learning, backend pour YOLOv8 |
| Ultralytics | 8.3.0 | Implémentation officielle YOLOv8-seg, gestion training/inférence |
| OpenCV | 4.11.0 | Traitement d'images (resize, contours, transformations géométriques) |
| Albumentations | 1.4.0 | Augmentations avancées avec support masques de segmentation |
| Torchvision | 0.20.0 | Transformations tensorielles, chargement de modèles pré-entraînés |
Frameworks Complémentaires
- MLflow 2.18.0 : Tracking d'expériences (hyperparamètres, métriques, artifacts)
- HuggingFace Datasets 3.5.0 : Téléchargement et gestion du FoodSeg103
- Pycocotools 2.0.8 : Calcul des métriques COCO-style (mAP, IoU)
Justification technique : Le choix d'Ultralytics YOLOv8-seg repose sur :
- État de l'art 2024 : Meilleur compromis vitesse/précision pour la segmentation temps réel
- Architecture unifiée : Détection bounding-box + masques de segmentation dans un seul modèle
- Pré-entraînement COCO : 80 classes génériques, transfert learning efficace vers aliments
Architecture YOLOv8-seg : Analyse Approfondie
Structure du Modèle
YOLOv8-seg est un modèle de segmentation d'instances one-stage qui étend YOLOv8 avec une branche de prédiction de masques. L'architecture suit le paradigme Anchor-Free avec détection par grille.
Composants principaux :
Input (640×640×3)
│
▼
┌────────────────────────────────────┐
│ Backbone: CSPDarknet53 │
│ - 5 stages de convolutions │
│ - Cross Stage Partial connections │
│ - Activations SiLU │
│ Output: Feature maps P3, P4, P5 │
│ (80×80, 40×40, 20×20) │
└─────────────┬──────────────────────┘
│
▼
┌────────────────────────────────────┐
│ Neck: PAN-FPN (Path Aggregation) │
│ - Top-down + Bottom-up fusion │
│ - Enrichit features multi-échelles│
└─────────────┬──────────────────────┘
│
├─────────────────┬──────────────┐
▼ ▼ ▼
┌──────────────────┐ ┌──────────────────┐ ┌──────────────────┐
│ Detection Head │ │ Segmentation │ │ Classification │
│ (Box regression) │ │ Head (Prototypes)│ │ Head (Scores) │
│ - x,y,w,h │ │ - 32 prototypes │ │ - 12 classes │
│ - Coordonnées │ │ - Masques 160×160│ │ - Softmax output │
└──────────────────┘ └──────────────────┘ └──────────────────┘
Modèles Fine-Tunés
Trois variantes entraînées :
| Variante | Dataset | Classes | Paramètres | Taille poids | mAP50 (Mask) | mAP50-95 (Mask) |
|---|---|---|---|---|---|---|
| YOLOv8s-seg | FoodSeg103 | 12 | 11.82M | 23 MB | 0.587 | 0.475 |
| YOLOv8m-seg | FoodSeg103 | 12 | 27.29M | 53 MB | 0.617 | 0.511 |
| YOLOv8m-seg Fusion | FoodSeg103 + UEC-FoodPix | 32 | 27.29M | 157 MB | 0.672 | 0.565 |
Modèle retenu : YOLOv8m-seg Fusion pour sa couverture alimentaire élargie (32 classes) et ses performances supérieures (+8.9% mAP50, +10.6% mAP50-95 par rapport au modèle FoodSeg103 seul).
Détails d'Implémentation
Le code src/models/yolov8_trainer.py encapsule la classe YOLO d'Ultralytics avec les spécificités suivantes :
# Chargement des poids pré-entraînés COCO
self.model = YOLO("yolov8m-seg.pt") # 80 classes COCO
# Fine-tuning avec Transfer Learning
results = self.model.train(
data="data/processed/dataset.yaml", # 12 classes FoodSeg103
epochs=200,
batch=12, # Limité par VRAM (NVIDIA RTX 2060, 12.9 GB)
imgsz=640,
device="cuda",
patience=50, # Early stopping
optimizer="SGD",
lr0=0.01, # Learning rate initial
lrf=0.01, # Learning rate final (cosine annealing)
momentum=0.937,
weight_decay=0.0005,
# Augmentations
mosaic=1.0, # Mosaic augmentation (4 images fusionnées)
mixup=0.1, # Mixup alpha
copy_paste=0.1, # Copy-paste augmentation
auto_augment="randaugment"
)
Fonction de perte composite (implémentée dans Ultralytics) :
- Box Loss : CIoU (Complete IoU) pour la régression des bounding boxes
- Classification Loss : Binary Cross-Entropy pour les scores de classe
- Mask Loss : Dice Loss + Binary Cross-Entropy sur les masques de segmentation
Pipeline de Prétraitement : Conversion Masques → Polygones YOLO
Problématique Technique
FoodSeg103 fournit des masques de segmentation sémantique (format PNG avec IDs de classe), tandis que YOLOv8-seg requiert des annotations polygonales au format texte :
Format FoodSeg103 (entrée):
- Fichier: mask.png (H×W, dtype=uint8)
- Chaque pixel contient l'ID de classe [0-103]
- 0 = background, 1-103 = classes alimentaires
Format YOLO (sortie):
- Fichier: label.txt (texte ASCII)
- Une ligne par instance: <class_id> <x1> <y1> <x2> <y2> ... <xn> <yn>
- Coordonnées normalisées [0, 1]
- Nombre variable de points par polygone
Algorithme de Conversion
L'implémentation dans src/data/preprocessing.py:86-138 suit cette séquence :
def mask_to_yolo_format(self, mask: np.ndarray, mask_value: int, class_id: int) -> List[float]:
"""
Convertit un masque multi-classe en polygone YOLO pour une classe donnée.
Args:
mask: Masque (H, W) avec IDs de classes FoodSeg103
mask_value: Valeur à chercher dans le masque (ID original 1-103)
class_id: ID YOLO à écrire dans le label (remappé 0-11)
"""
Étapes de l'algorithme :
-
Binarisation par classe :
binary_mask = (mask == mask_value).astype(np.uint8)
# Isole une seule classe (ex: tous les pixels où classe=58 pour "bread") -
Détection de contours (OpenCV) :
contours, _ = cv2.findContours(
binary_mask,
cv2.RETR_EXTERNAL, # Contours externes uniquement (pas de trous)
cv2.CHAIN_APPROX_SIMPLE # Compression des segments colinéaires
)- cv2.RETR_EXTERNAL : Ignore les contours imbriqués (gestion simplifiée des instances multiples)
- cv2.CHAIN_APPROX_SIMPLE : Réduit le nombre de points (stocke uniquement les extrémités de segments)
-
Sélection du plus grand contour :
largest_contour = max(contours, key=cv2.contourArea)
# Gestion simplifiée : 1 polygone par classe par image
# Limitation identifiée : ne gère pas les instances multiples d'une même classe -
Filtrage anti-bruit :
if cv2.contourArea(largest_contour) <50:
return []
# Ignore les objets <50 pixels (artefacts de labellisation) -
Simplification polygonale (Douglas-Peucker) :
epsilon = 0.005 * cv2.arcLength(largest_contour, True)
approx = cv2.approxPolyDP(largest_contour, epsilon, True)
# Réduit le nombre de points tout en préservant la forme
# epsilon=0.5% du périmètre : compromis fichier léger / précision -
Normalisation des coordonnées :
h, w = mask.shape
normalized_coords = []
for point in approx:
x, y = point[0]
normalized_coords.extend([x / w, y / h])
# Coordonnées en [0, 1] pour l'indépendance à la résolution -
Sécurité numérique :
normalized_coords = np.clip(normalized_coords, 0.0, 1.0).tolist()
# Empêche les valeurs hors limites dues aux erreurs d'arrondi
return [class_id] + normalized_coords
Gestion du Remapping de Classes
Problème critique résolu : FoodSeg103 possède 103 classes avec IDs non-contigus (1-103), mais YOLOv8 nécessite des IDs contigus (0-11 pour 12 classes).
Solution implémentée (voir notebooks/02_preprocessing.ipynb, cellules 10-11) :
# Étape 1 : Analyse de fréquence sur 4983 images
class_freq = Counter()
for sample in dataset:
class_freq.update(sample['classes_on_image'])
# Étape 2 : Sélection des 12 classes les plus fréquentes
top_classes_with_counts = class_freq.most_common(12)
# Résultat: [58 (bread, 991), 84 (onion, 881), 48 (chicken_duck, 848), ...]
# Étape 3 : Création du mapping bijectif
original_to_yolo = {}
for yolo_id, (orig_id, count) in enumerate(top_classes_with_counts):
original_to_yolo[orig_id] = yolo_id
# Exemple: {58: 0, 84: 1, 48: 2, 52: 3, ...}
# Étape 4 : Application lors de la conversion
for original_cls_id in np.unique(mask_resized):
if original_cls_id not in original_to_yolo:
continue # Ignore les classes non retenues
yolo_class_id = original_to_yolo[original_cls_id]
yolo_ann = preprocessor.mask_to_yolo_format(
mask_resized,
mask_value=original_cls_id, # Cherche la valeur d'origine (ex: 58)
class_id=yolo_class_id # Écrit l'ID remappé (ex: 0)
)
Classes finales retenues :
| YOLO ID | FoodSeg103 ID | Nom | Fréquence |
|---|---|---|---|
| 0 | 58 | bread | 991 images |
| 1 | 84 | onion | 881 images |
| 2 | 48 | chicken_duck | 848 images |
| 3 | 52 | sauce | 818 images |
| 4 | 73 | tomato | 790 images |
| 5 | 70 | potato | 785 images |
| 6 | 46 | steak | 728 images |
| 7 | 87 | french_bean | 704 images |
| 8 | 89 | mixed_vegetables | 636 images |
| 9 | 8 | ice_cream | 636 images |
| 10 | 47 | pork | 474 images |
| 11 | 66 | rice | 464 images |
Justification : Réduction de 103 à 12 classes pour :
- Concentrer l'apprentissage sur les aliments les plus représentatifs
- Éviter le surapprentissage sur classes rares (<50 images)
- Équilibrer relativement le dataset (ratio max/min = 2.1:1)
Pipeline de Fusion : FoodSeg103 + UEC-FoodPix (32 classes)
Motivation
Le modèle initial entraîné sur FoodSeg103 (12 classes) présentait des limitations :
- Couverture alimentaire restreinte (pas de poisson, pizza, hamburger, nouilles, etc.)
- Dataset limité à 4 526 images
- Biais géographique (cuisine principalement occidentale/chinoise)
Pour y remédier, un dataset fusionné a été construit en combinant FoodSeg103 et UEC-FoodPix Complete, portant la couverture à 32 classes alimentaires et 15 994 images.
Datasets Sources
| Dataset | Images | Classes originales | Format masques |
|---|---|---|---|
| FoodSeg103 | 7 118 | 103 + background | Pixel-wise (IDs de classe) |
| UEC-FoodPix Complete | 10 000+ | 102 | Canal rouge du PNG |
Mapping vers 32 Classes Unifiées
Les 32 classes cibles ont été définies par intersection et complémentarité des deux datasets (voir notebooks/01_fusion_exploration.ipynb) :
| ID | Classe | ID | Classe | ID | Classe | ID | Classe |
|---|---|---|---|---|---|---|---|
| 0 | rice | 8 | sausage | 16 | soup | 24 | salad |
| 1 | bread | 9 | tofu | 17 | sauce | 25 | cheese |
| 2 | egg | 10 | noodles | 18 | eggplant | 26 | soy_beans |
| 3 | chicken | 11 | pasta | 19 | spinach | 27 | beverage |
| 4 | pork | 12 | pizza | 20 | cabbage | 28 | pepper |
| 5 | steak | 13 | hamburger | 21 | mixed_vegetables | 29 | carrot |
| 6 | fish | 14 | french_fries | 22 | dumplings | 30 | cake |
| 7 | shrimp | 15 | potato | 23 | fried_meat | 31 | onion |
Pipeline de Fusion (notebooks/02_data_fusion_and_cleaning.ipynb)
┌─────────────────────────┐ ┌─────────────────────────┐
│ FoodSeg103 │ │ UEC-FoodPix Complete │
│ 7 118 images │ │ 10 000+ images │
│ Masques: pixel IDs │ │ Masques: canal rouge │
└──────────┬──────────────┘ └──────────┬──────────────┘
│ │
▼ ▼
┌─────────────────────────────────────────────────┐
│ Mapping classes → 32 classes cibles │
│ - Résolution conflits d'occlusion (priorité) │
│ - Conversion masques → polygones YOLO │
│ - Filtrage images sans classes cibles │
└──────────┬──────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────┐
│ Dataset Fusionné │
│ - 6 515 images FoodSeg103 (conservées) │
│ - 9 479 images UEC-FoodPix (conservées) │
│ - Total: 15 994 images │
└──────────┬──────────────────────────────────────┘
│
▼ Split stratifié 70/15/15
┌─────────────────────────────────────────────────┐
│ Train: 11 195 images │
│ Val: 2 399 images │
│ Test: 2 400 images │
│ → data/processed/fusion_32cls/ │
└─────────────────────────────────────────────────┘
Points techniques clés :
- Gestion des conflits d'occlusion : Système de priorité par classe pour résoudre les chevauchements de masques
- Distribution équilibrée : Répartition proportionnelle des sources (FoodSeg103 / UEC-FoodPix) dans chaque split
- Format standardisé : Conversion uniforme au format YOLO polygonal avec
dataset_fusion.yaml
Distribution des Labels (Fusion)
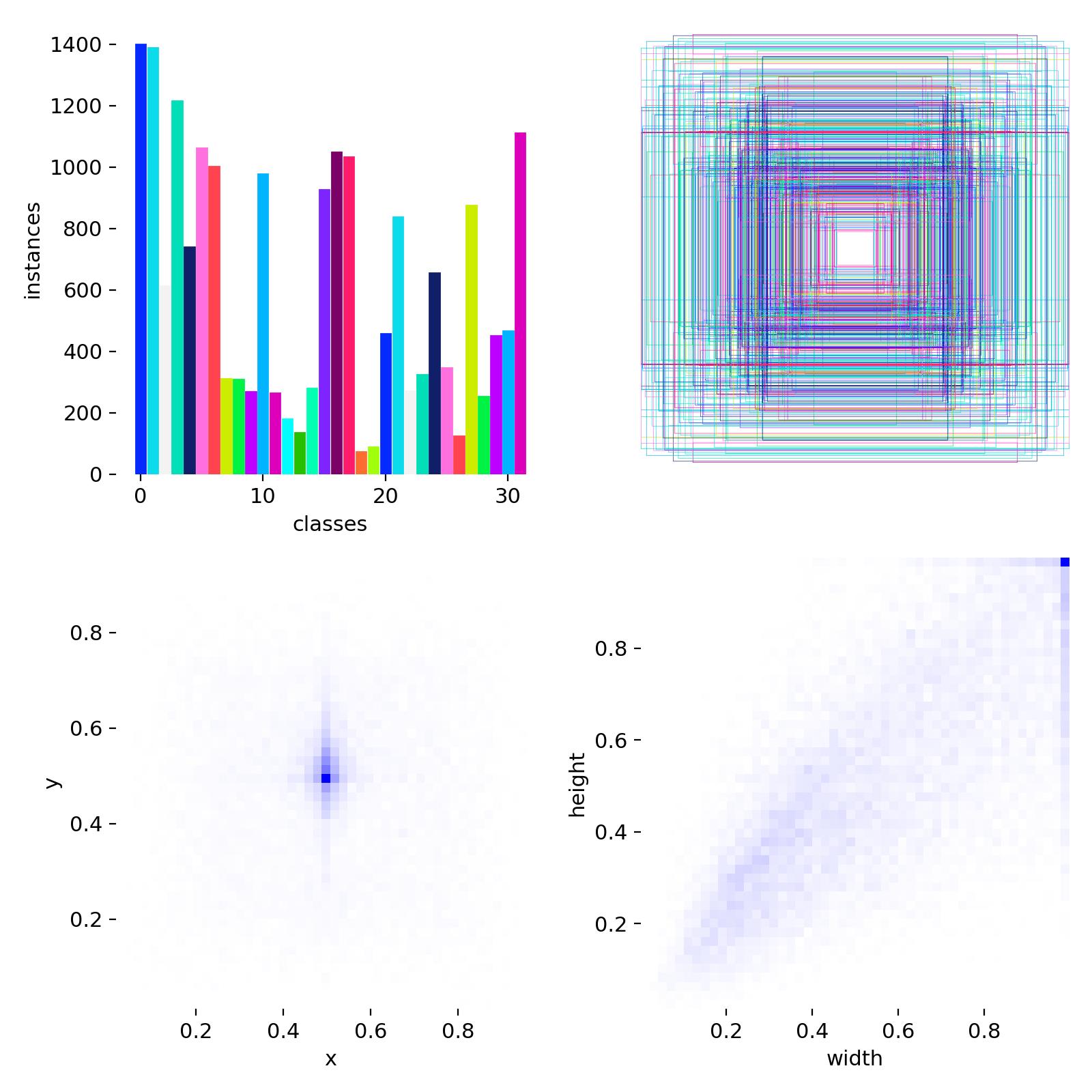
Distribution des 32 classes, tailles de bounding boxes et positions des objets dans le dataset fusionné
Hyperparamètres d'Entraînement (Fusion)
Extrait de models/yolov8_fusion/args.yaml :
task: segment
model: yolov8m-seg.pt # Poids pré-entraînés COCO
data: fusion_32cls/dataset_fusion.yaml # 32 classes fusionnées
epochs: 150 # Réduit vs 200 (dataset plus grand)
batch: 16 # Augmenté vs 12 (plus de données)
imgsz: 640
patience: 50
optimizer: SGD
lr0: 0.01
lrf: 0.01
momentum: 0.937
weight_decay: 0.0005
mosaic: 1.0
mixup: 0.1
copy_paste: 0.1
Différences avec l'entraînement FoodSeg103 :
| Paramètre | FoodSeg103 (ancien) | Fusion (nouveau) |
|---|---|---|
| Dataset | 4 526 images | 15 994 images |
| Classes | 12 | 32 |
| Époques | 200 | 150 |
| Batch size | 12 | 16 |
| Images d'entraînement | 3 168 | 11 195 |
La réduction du nombre d'époques (200 → 150) est justifiée par le dataset 3.5x plus grand, offrant plus de diversité par époque.
Transformations d'Images : Pipeline Albumentations
Séquence de Prétraitement
Le pipeline d'augmentations (src/data/preprocessing.py:27-67) applique les transformations suivantes dans l'ordre strict :
A.Compose([
# 1. REDIMENSIONNEMENT
A.Resize(640, 640),
# Interpolation: INTER_LINEAR (par défaut Albumentations)
# Note: Downscaling depuis résolution moyenne 798×652 px
# 2. AUGMENTATIONS GÉOMÉTRIQUES
A.HorizontalFlip(p=0.5),
# Invariance horizontale (plats vus de dessus)
# Ne pas utiliser VerticalFlip (orientation réaliste préservée)
A.Rotate(limit=15, p=0.3),
# Rotation ±15° (variabilité angle de prise de vue)
# Interpolation: INTER_LINEAR, border_mode: BORDER_REFLECT_101
# 3. AUGMENTATIONS COLORIMÉTRIQUES
A.RandomBrightnessContrast(
brightness_limit=0.2, # ±20% luminosité
contrast_limit=0.2, # ±20% contraste
p=0.3
),
# Simule conditions d'éclairage variées
A.HueSaturationValue(
hue_shift_limit=10, # ±10° rotation teinte
sat_shift_limit=20, # ±20% saturation
val_shift_limit=10, # ±10% intensité
p=0.3
),
# Robustesse aux variations de balance des blancs
# 4. DROPOUT SPATIAL
A.CoarseDropout(
max_holes=8,
max_height=32,
max_width=32,
p=0.2
),
# Simule occlusions partielles (couverts, mains, etc.)
# Forces le modèle à apprendre des features locales
# 5. NORMALISATION (STANDARD IMAGENET)
A.Normalize(
mean=[0.485, 0.456, 0.406], # RGB ImageNet
std=[0.229, 0.224, 0.225]
),
# Standardisation des canaux pour convergence stable
# Exploite les statistiques du pré-entraînement COCO
])
Transformations au Niveau Pixel
Redimensionnement avec INTER_AREA (appliqué dans notebooks/02_preprocessing.ipynb) :
img_resized = cv2.resize(img, (640, 640), interpolation=cv2.INTER_AREA)
mask_resized = cv2.resize(mask, (640, 640), interpolation=cv2.INTER_NEAREST)
Justifications techniques :
- INTER_AREA pour images : Calcul de la moyenne pondérée des pixels voisins lors du downscaling, évite l'aliasing (préserve les détails fins, optimal pour réduction de résolution)
- INTER_NEAREST pour masques : Préserve les valeurs exactes des IDs de classe (pas d'interpolation entre classes distinctes)
Conversion d'espaces colorimétriques :
# Lecture OpenCV (BGR)
img = cv2.imread(image_path) # Shape: (H, W, 3), BGR order
# Conversion RGB pour cohérence
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# ... transformations Albumentations (opèrent en RGB) ...
# Reconversion BGR pour sauvegarde OpenCV
cv2.imwrite(output_path, cv2.cvtColor(img_resized, cv2.COLOR_RGB2BGR))
Point d'attention : FoodSeg103 (HuggingFace) charge les images en RGB natif (PIL), donc pas de conversion nécessaire lors du chargement initial.
Visualisation des Augmentations
Exemples de batches d'entraînement avec augmentations appliquées :

Figure 1 : Premier batch d'entraînement montrant les augmentations (mosaic, mixup, transformations)

Figure 2 : Deuxième batch d'entraînement avec variété d'augmentations

Figure 3 : Troisième batch montrant la diversité des scènes alimentaires
Observations :
- Les augmentations mosaic combinent 4 images pour créer des scènes plus complexes
- Variété importante de contextes et d'arrangements d'aliments
- Les masques de segmentation sont préservés malgré les transformations
- Bon équilibre entre les différentes classes alimentaires
Batches d'entraînement du modèle Fusion (32 classes) :

Figure 4 : Batch d'entraînement Fusion montrant la diversité des 32 classes (deux datasets combinés)

Figure 5 : Deuxième batch Fusion avec les nouvelles classes (pizza, hamburger, noodles, etc.)
Comparaison : Les batches du modèle Fusion présentent une plus grande variété d'aliments et de styles culinaires (cuisine japonaise, occidentale, chinoise) grâce à la combinaison des deux datasets.
Distribution des Labels
Statistiques des classes dans le dataset FoodSeg103 :
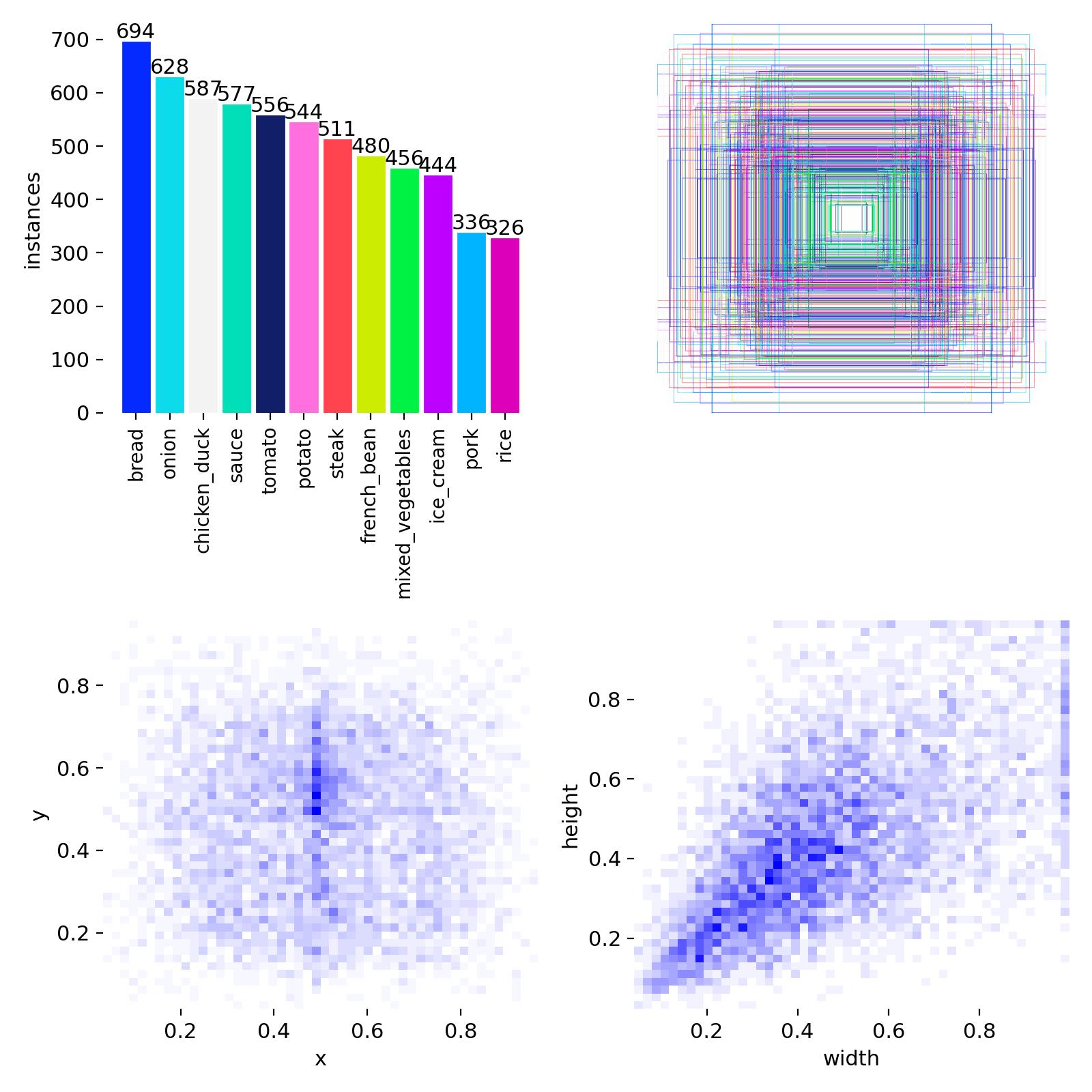
Figure 6 : Distribution des 12 classes FoodSeg103, tailles de bounding boxes et positions des objets
Statistiques des classes dans le dataset Fusion :
Figure 7 : Distribution des 32 classes fusionnées, tailles de bounding boxes et positions des objets
Analyse comparative de la distribution :
- Le dataset Fusion couvre 32 classes contre 12, avec une meilleure représentation de la diversité culinaire
- Le volume de données est 3.5x supérieur (15 994 vs 4 526 images)
- Variété de tailles d'objets préservée dans les deux datasets
- Positions réparties sur toute l'image (pas de biais spatial)
Split Stratifié et Contrôle du Background
Stratégie de Partitionnement
Le split train/val/test est implémenté avec stratification par classe principale (voir notebooks/02_preprocessing.ipynb, cellules 12-13) :
def create_filtered_stratified_split(dataset, top_classes,
train_r=0.7, val_r=0.15, test_r=0.15,
max_bg_ratio=0.1, random_state=42):
Étapes de l'algorithme :
-
Filtrage foreground/background :
foreground_indices = [] # Images contenant ≥1 top-classe
background_indices = [] # Images sans top-classes (0 ou classes rares)
strat_labels = [] # Étiquette de stratification (première top-classe)
for idx, sample in enumerate(dataset):
classes_on_img = sample['classes_on_image']
top_on_img = [c for c in classes_on_img if c in top_classes]
if len(top_on_img) > 0:
foreground_indices.append(idx)
strat_labels.append(top_on_img[0]) # Stratifie sur classe dominante
else:
background_indices.append(idx) -
Échantillonnage du background :
n_bg_to_keep = int(len(foreground_indices) * max_bg_ratio)
sampled_bg = np.random.choice(background_indices, size=n_bg_to_keep, replace=False)
# Résultat: 4115 foreground + 411 background (10%) = 4526 images totalesJustification : Limite les images vides à 10% pour éviter un biais de prédiction vers le background (classe négative).
-
Gestion des singletons :
counts = Counter(all_labels)
safe_labels = [label if counts[label] >= 2 else 0 for label in all_labels]
# Regroupe les classes avec <2 échantillons dans la classe 0 (background)
# Évite l'exception de sklearn.train_test_split en stratification -
Split en deux étapes :
# Étape 1: Train vs (Val+Test)
train_idx, temp_idx = train_test_split(
all_indices, test_size=0.3, stratify=safe_labels, random_state=42
)
# Étape 2: Val vs Test
val_idx, test_idx = train_test_split(
temp_idx, test_size=0.5, stratify=temp_labels, random_state=42
)
Résultats :
| Split | Images Totales | Avec Labels | Sans Labels | Couverture |
|---|---|---|---|---|
| Train | 3168 | 2880 | 288 | 90.9% |
| Val | 679 | 617 | 62 | 90.9% |
| Test | 679 | 618 | 61 | 91.0% |
Observation : 90.9% de couverture = ~10% d'images background dans chaque split (objectif respecté).
Hyperparamètres d'Entraînement
Configuration YOLOv8m-seg
Extrait de models/yolov8m_foodseg103/args.yaml :
task: segment
mode: train
model: yolov8m-seg.pt # Poids pré-entraînés COCO (27.29M params)
# Dataset
data: C:\...\data\processed\dataset.yaml
epochs: 200
patience: 50 # Early stopping si mAP50 ne progresse pas pendant 50 époques
# Hardware
batch: 12 # Réduit vs YOLOv8s (24) pour tenir en VRAM
device: 0 # CUDA GPU 0 (NVIDIA RTX 2060, 12.9 GB)
workers: 4 # DataLoader threads
# Image
imgsz: 640 # Résolution d'entrée (640×640)
rect: False # Pas de rectangular training (images carrées)
# Optimizer (SGD standard)
optimizer: SGD
lr0: 0.01 # Learning rate initial
lrf: 0.01 # Learning rate final (100× réduction)
momentum: 0.937
weight_decay: 0.0005
warmup_epochs: 3.0
warmup_momentum: 0.8
warmup_bias_lr: 0.1
# Augmentations
hsv_h: 0.015 # Hue augmentation
hsv_s: 0.7 # Saturation augmentation
hsv_v: 0.4 # Value augmentation
degrees: 0.0 # Rotation (désactivé, géré par Albumentations)
translate: 0.1 # Translation ±10%
scale: 0.5 # Scaling 0.5-1.5×
shear: 0.0 # Shearing désactivé
perspective: 0.0 # Perspective warp désactivé
flipud: 0.0 # Vertical flip désactivé (orientation importante)
fliplr: 0.5 # Horizontal flip activé
mosaic: 1.0 # Mosaic augmentation (4 images fusionnées)
mixup: 0.1 # Mixup augmentation (alpha=0.1)
copy_paste: 0.1 # Copy-paste instances entre images
# Loss weights
box: 7.5 # Box regression loss weight
cls: 0.5 # Classification loss weight
dfl: 1.5 # Distribution Focal Loss weight
pose: 12.0 # (N/A pour segmentation)
kobj: 1.0 # Keypoint objectness (N/A)
# Validation
val: True
save: True
save_period: 15 # Sauvegarde checkpoint tous les 15 époques
plots: True # Génère courbes d'entraînement
Métriques COCO
Le modèle est évalué avec les métriques standard COCO Instance Segmentation :
| Métrique | Définition | YOLOv8m (12 cls) | YOLOv8m Fusion (32 cls) |
|---|---|---|---|
| mAP50 (Mask) | Mean Average Precision @ IoU=0.50 | 0.617 | 0.672 |
| mAP50-95 (Mask) | mAP moyenné sur IoU ∈ [0.50:0.95:0.05] | 0.511 | 0.565 |
| Precision | TP / (TP + FP) @ conf > 0.25 | 0.605 | 0.682 |
| Recall | TP / (TP + FN) @ conf > 0.25 | 0.578 | 0.632 |
Formule mAP50-95 :
mAP50-95 = (1/10) × Σ(i=0 to 9) mAP@IoU=(0.50 + i×0.05)
Cette métrique stricte pénalise les prédictions avec IoU <0.95, reflétant mieux la qualité de segmentation au niveau pixel.
Intégration MLflow
Architecture de Tracking
Le système utilise MLflow 2.18.0 avec backend SQLite local (notebooks/mlflow.db) pour tracer tous les entraînements.
Implémentation (src/models/yolov8_trainer.py:52-86) :
with mlflow.start_run():
# Logging hyperparamètres
mlflow.log_param("model", self.model_name)
mlflow.log_param("epochs", epochs)
mlflow.log_param("batch_size", batch)
mlflow.log_param("image_size", imgsz)
mlflow.log_param("device", device)
# Entraînement YOLOv8
results = self.model.train(data=data_yaml, epochs=epochs, ...)
# Logging métriques finales
metrics = results.results_dict
mlflow.log_metrics({
"mAP50": metrics.get("metrics/mAP50(B)", 0.0), # Box mAP
"mAP50-95": metrics.get("metrics/mAP50-95(B)", 0.0), # Box mAP strict
"precision": metrics.get("metrics/precision(B)", 0.0),
"recall": metrics.get("metrics/recall(B)", 0.0),
})
# Sauvegarde du meilleur modèle dans MLflow artifacts
best_model_path = Path(results.save_dir) / "weights" / "best.pt"
if best_model_path.exists():
mlflow.log_artifact(str(best_model_path), "model")
Visualisation des Expériences
Lancement de l'UI MLflow :
cd notebooks
mlflow ui --backend-store-uri sqlite:///mlflow.db --port 5000
Informations trackées :
- Hyperparamètres : model, epochs, batch_size, image_size, device
- Métriques : mAP50, mAP50-95, precision, recall (évolution par époque)
- Artifacts : best.pt (poids du modèle), confusion matrix, PR curves, F1 curves
Export ONNX et Quantification
Conversion ONNX FP16
Le notebook 04_quantization_export.ipynb exporte le modèle optimisé pour l'inférence :
from ultralytics import YOLO
# Chargement du meilleur checkpoint PyTorch
model = YOLO('/img/models/yolov8m_foodseg103/weights/best.pt')
# Export ONNX avec quantification FP16
model.export(
format='onnx',
half=True, # Quantification FP16 (float16)
simplify=True, # Optimisation du graphe ONNX
opset=12, # ONNX opset 12 (compatible TensorRT 8+)
dynamic=False, # Shape statique (batch=1, 3, 640, 640)
imgsz=640
)
Résultat :
- Fichier :
models/yolov8m_foodseg103/weights/best.onnx - Taille : 52.1 MB (vs 52.3 MB PyTorch .pt)
- Réduction : Négligeable (quantification FP16 sur poids déjà compressés)
- Temps d'export : 4.4 secondes
Bénéfices de l'Export ONNX
- Portabilité : Exécution sur backend non-PyTorch (ONNX Runtime, TensorRT, CoreML)
- Optimisation du graphe : Fusion d'opérations (Conv+BN+ReLU), élimination de nœuds morts
- Quantification FP16 : Réduction de 50% de la mémoire avec perte de précision <1%
- Intégration production : Compatible navigateur web (ONNX Runtime Web), edge devices, serveurs
Limitation identifiée : Pas de quantification INT8 (nécessiterait calibration dataset, post-training quantization non implémentée).