Installation Et Reproduction
Prérequis Système
| Composant | Spécification Minimale | Configuration Testée |
|---|---|---|
| OS | Windows 10/11, Ubuntu 20.04+, macOS 12+ | Windows 11 Pro |
| GPU | NVIDIA (Compute Capability ≥ 6.0), 8 GB VRAM | NVIDIA RTX 2060 (12.9 GB) |
| CUDA | 11.8 ou 12.6 | 12.6 |
| RAM | 16 GB | 32 GB |
| Stockage | 20 GB libre (5 GB dataset + 1 GB modèles + 14 GB cache) | 80 GB libre |
| Python | 3.9-3.11 | 3.11.5 |
Note : Entraînement possible sur CPU (très lent, ×50 temps), validation uniquement pour prototypage.
Installation Pas-à-Pas
Étape 1 : Clonage du Dépôt
git clone https://github.com/EpitechPGE45-2025/G-AIA-910-PAR-9-2-computervision-12
cd nutriscan
Étape 2 : Environnement Virtuel
# Création environnement
python -m venv venv
# Activation
# Windows:
venv\Scripts\activate
# Linux/macOS:
source venv/bin/activate
Étape 3 : Installation des Dépendances
Pour GPU (NVIDIA CUDA 12.6) :
# Installer PyTorch avec support CUDA
pip install torch==2.9.0 torchvision==0.20.0 --index-url https://download.pytorch.org/whl/cu126
# Installer les autres dépendances
pip install -r requirements.txt
Pour CPU uniquement :
pip install torch==2.9.0 torchvision==0.20.0 --index-url https://download.pytorch.org/whl/cpu
pip install -r requirements.txt
Vérification CUDA :
import torch
print(f"CUDA disponible: {torch.cuda.is_available()}")
print(f"Version CUDA: {torch.version.cuda}")
print(f"GPU: {torch.cuda.get_device_name(0)}")
Sortie attendue :
CUDA disponible: True
Version CUDA: 12.6
GPU: NVIDIA GeForce RTX 2060
Étape 4 : Téléchargement du Dataset
Option A : Automatique (recommandé) :
# Dans un notebook ou script Python
from src.data.download import download_foodseg103
download_foodseg103(
save_dir="data/raw",
subset_ratio=None # None = dataset complet (4983 images)
)
Option B : Manuel :
- Visiter https://huggingface.co/datasets/kuzand/foodseg103
- Télécharger le split
train(4.5 GB) - Extraire dans
data/raw/foodseg103/
Vérification :
ls data/raw/foodseg103/train/
# Attendu: data-00000-of-00002.arrow, data-00001-of-00002.arrow, dataset_info.json
Étape 5 : Prétraitement
Option A : Pipeline FoodSeg103 uniquement (12 classes)
# Lancer Jupyter
jupyter notebook
# Ouvrir et exécuter séquentiellement:
# 1. notebooks/01_data_exploration.ipynb (EDA)
# 2. notebooks/02_preprocessing.ipynb (génère data/processed/)
Vérification :
import yaml
with open('data/processed/dataset.yaml') as f:
config = yaml.safe_load(f)
print(f"Classes: {len(config['names'])}") # Attendu: 12
Option B : Pipeline Fusion FoodSeg103 + UEC-FoodPix (32 classes, recommandé)
# Ouvrir et exécuter séquentiellement:
# 1. notebooks/01_fusion_exploration.ipynb (EDA + mapping des deux datasets)
# 2. notebooks/02_data_fusion_and_cleaning.ipynb (génère data/processed/fusion_32cls/)
Vérification :
import yaml
with open('data/processed/fusion_32cls/dataset_fusion.yaml') as f:
config = yaml.safe_load(f)
print(f"Classes: {len(config['names'])}") # Attendu: 32
Étape 6 : Entraînement YOLOv8
Option A : Modèle Fusion 32 classes (recommandé) :
# Ouvrir notebooks/03_train_yolov8_fusion.ipynb
# Exécuter toutes les cellules
Ou via script Python :
from src.models.yolov8_trainer import YOLOv8Trainer
trainer = YOLOv8Trainer(
model_name="yolov8m-seg.pt",
experiment_name="nutriscan_fusion"
)
results = trainer.train(
data_yaml="data/processed/fusion_32cls/dataset_fusion.yaml",
epochs=150,
batch=16, # Ajuster selon VRAM disponible
imgsz=640,
device="cuda",
patience=50,
save_period=15
)
print(f"mAP50 final: {results['metrics/mAP50(M)']:.3f}")
Option B : Modèle FoodSeg103 uniquement (12 classes) :
from src.models.yolov8_trainer import YOLOv8Trainer
trainer = YOLOv8Trainer(
model_name="yolov8m-seg.pt",
experiment_name="nutriscan_production"
)
results = trainer.train(
data_yaml="data/processed/dataset.yaml",
epochs=200,
batch=12,
imgsz=640,
device="cuda",
patience=50,
save_period=15
)
print(f"mAP50 final: {results['metrics/mAP50(M)']:.3f}")
Temps d'entraînement estimés :
| GPU | Modèle | Batch Size | Époques | Temps estimé |
|---|---|---|---|---|
| RTX 2060 (12 GB) | Fusion 32cls | 16 | 150 | ~10h |
| RTX 2060 (12 GB) | FoodSeg103 12cls | 12 | 200 | ~8h20 |
| RTX 3090 (24 GB) | Fusion 32cls | 32 | 150 | ~5h |
| CPU (32 GB RAM) | FoodSeg103 12cls | 4 | 200 | ~6 jours |
Étape 7 : Validation
Modèle Fusion (32 classes) :
from ultralytics import YOLO
model = YOLO('models/yolov8_fusion/weights/best.pt')
metrics = model.val(
data='data/processed/fusion_32cls/dataset_fusion.yaml',
split='test'
)
print(f"mAP50 (Mask): {metrics.seg.map50:.3f}")
print(f"mAP50-95 (Mask): {metrics.seg.map:.3f}")
Résultats attendus (Fusion) :
mAP50 (Mask): 0.672
mAP50-95 (Mask): 0.565
Modèle FoodSeg103 (12 classes) :
model = YOLO('models/yolov8m_foodseg103/weights/best.pt')
metrics = model.val(
data='data/processed/dataset.yaml',
split='test'
)
print(f"mAP50 (Mask): {metrics.seg.map50:.3f}")
print(f"mAP50-95 (Mask): {metrics.seg.map:.3f}")
# Attendu: mAP50=0.617, mAP50-95=0.511
Comparaison visuelle des prédictions :
| FoodSeg103 (12 classes) | Fusion (32 classes) |
|---|---|
 |  |
Prédictions sur les batches de validation : le modèle Fusion détecte plus de catégories d'aliments
Étape 8 : Inférence sur Image
from ultralytics import YOLO
import cv2
model = YOLO('models/yolov8m_foodseg103/weights/best.pt')
# Prédiction
results = model.predict(
source='path/to/food_image.jpg',
conf=0.25, # Seuil de confiance
save=True, # Sauvegarde visualisation
project='runs/predict',
name='test'
)
# Accès aux résultats
for r in results:
boxes = r.boxes # Bounding boxes
masks = r.masks # Masques de segmentation
classes = r.boxes.cls # IDs de classe
confs = r.boxes.conf # Scores de confiance
print(f"Détecté {len(boxes)} objets:")
for i, (cls, conf) in enumerate(zip(classes, confs)):
class_name = model.names[int(cls)]
print(f" {i+1}. {class_name} (confiance: {conf:.2f})")
Export ONNX
from ultralytics import YOLO
model = YOLO('models/yolov8m_foodseg103/weights/best.pt')
# Export ONNX FP16
model.export(
format='onnx',
half=True, # Quantification FP16
simplify=True,
opset=12,
imgsz=640
)
print("Export réussi: models/yolov8m_foodseg103/weights/best.onnx")
Utilisation du modèle ONNX :
import onnxruntime as ort
import numpy as np
# Chargement
session = ort.InferenceSession('models/yolov8m_foodseg103/weights/best.onnx')
# Prétraitement (identique à YOLOv8)
img = cv2.imread('image.jpg')
img = cv2.resize(img, (640, 640))
img = img.transpose(2, 0, 1) # HWC → CHW
img = img.astype(np.float32) / 255.0
img = np.expand_dims(img, axis=0) # Batch dimension
# Inférence
outputs = session.run(None, {'images': img})
Lancement MLflow UI
cd notebooks
mlflow ui --backend-store-uri sqlite:///mlflow.db --port 5000
# Ouvrir http://localhost:5000 dans le navigateur
Fonctionnalités MLflow :
- Comparaison de runs (hyperparamètres vs métriques)
- Visualisation des courbes d'apprentissage
- Téléchargement des artifacts (modèles, graphiques)
Accès aux métriques :
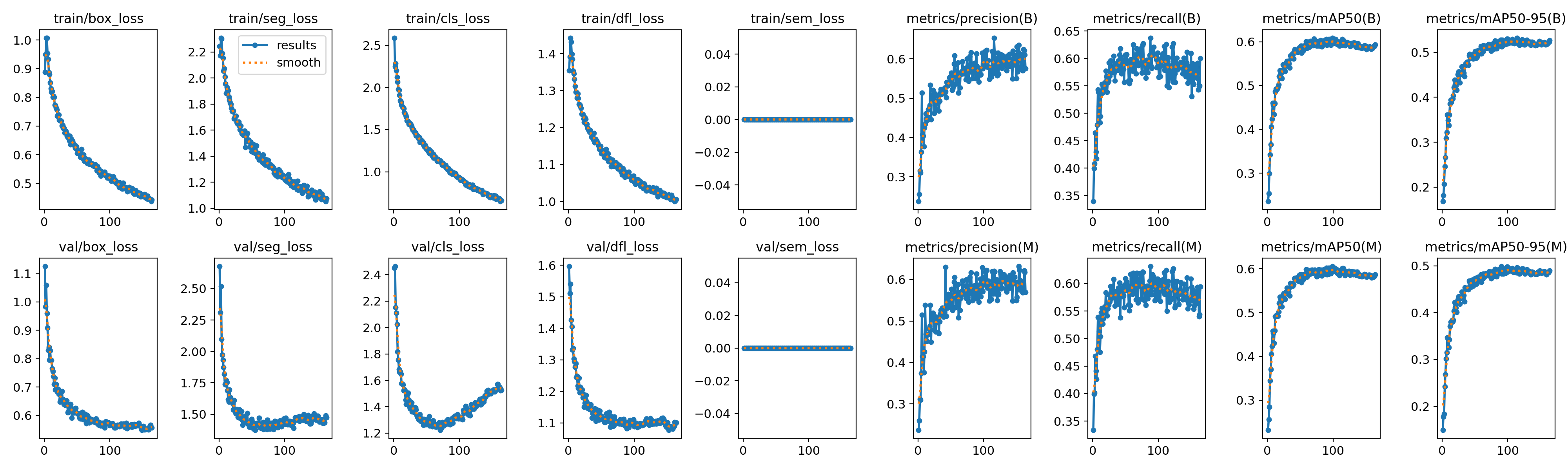
Courbes d'apprentissage complètes disponibles dans MLflow UI et dans les fichiers de résultats YOLOv8