Résultats Expérimentaux
Métriques Globales
Comparaison des trois modèles
| Modèle | Dataset | Classes | mAP50 (Box) | mAP50-95 (Box) | mAP50 (Mask) | mAP50-95 (Mask) | Précision | Recall | Taille |
|---|---|---|---|---|---|---|---|---|---|
| YOLOv8s-seg | FoodSeg103 | 12 | 0.586 | 0.496 | 0.587 | 0.475 | 0.578 | 0.542 | 23 MB |
| YOLOv8m-seg | FoodSeg103 | 12 | 0.620 | 0.541 | 0.617 | 0.511 | 0.605 | 0.578 | 53 MB |
| YOLOv8m Fusion | FoodSeg103 + UEC-FoodPix | 32 | 0.675 | 0.593 | 0.672 | 0.565 | 0.682 | 0.632 | 157 MB |
Gains du modèle Fusion vs YOLOv8m FoodSeg103
| Métrique | YOLOv8m (12 cls) | Fusion (32 cls) | Gain |
|---|---|---|---|
| mAP50 (Mask) | 0.617 | 0.672 | +8.9% |
| mAP50-95 (Mask) | 0.511 | 0.565 | +10.6% |
| mAP50 (Box) | 0.620 | 0.675 | +8.9% |
| mAP50-95 (Box) | 0.541 | 0.593 | +9.6% |
| Précision | 0.605 | 0.682 | +12.7% |
| Recall | 0.578 | 0.632 | +9.3% |
Observations :
- Le modèle Fusion surpasse l'ancien modèle sur toutes les métriques, malgré 2.7x plus de classes
- Le gain est significatif (+8-13%) grâce au dataset 3.5x plus grand et plus diversifié
- La précision est la métrique avec le plus grand gain (+12.7%), indiquant moins de faux positifs
- Le modèle Fusion a un poids plus élevé (157 MB vs 53 MB) en raison des 32 classes
Comparaison Visuelle des Trois Modèles
| YOLOv8s (12 classes) | YOLOv8m (12 classes) | YOLOv8m Fusion (32 classes) |
|---|---|---|
 |  |  |
Comparaison directe des prédictions : le modèle Fusion détecte plus de classes avec une meilleure précision.
Performance par Classe (YOLOv8m Fusion, 32 classes)
Top Performing Classes
| Classe | mAP50 | mAP50-95 |
|---|---|---|
| rice | 0.876 | 0.819 |
| hamburger | 0.903 | 0.852 |
| noodles | 0.891 | 0.833 |
| pizza | 0.885 | 0.833 |
Analyse : Les classes avec des formes distinctes et des textures homogènes (hamburger, pizza) obtiennent les meilleurs résultats. Le riz bénéficie d'une forte représentation dans les deux datasets (cuisine asiatique).
Matrice de Confusion (Fusion, 32 classes)
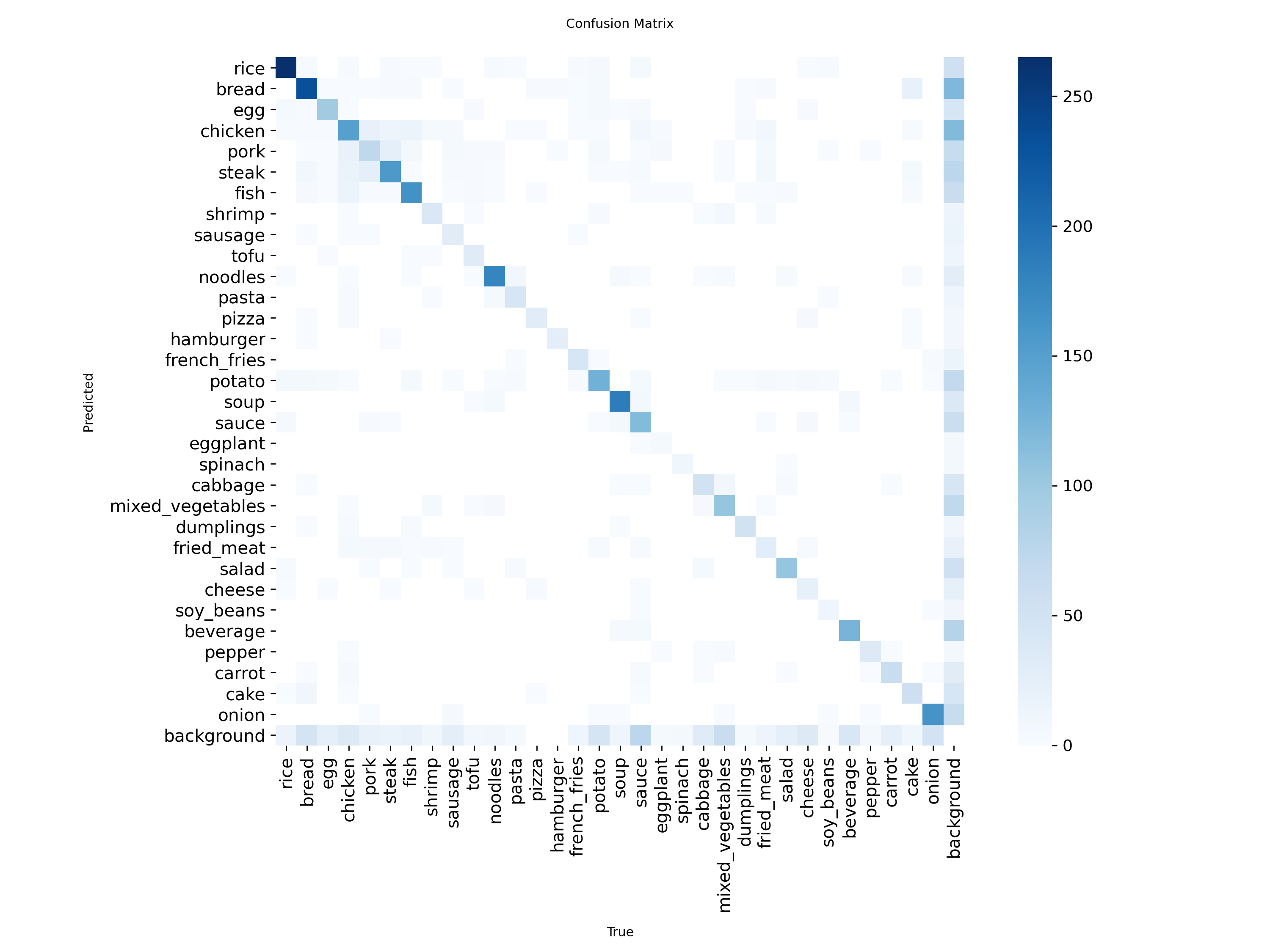
Matrice de confusion du modèle Fusion sur le test set (32 classes)
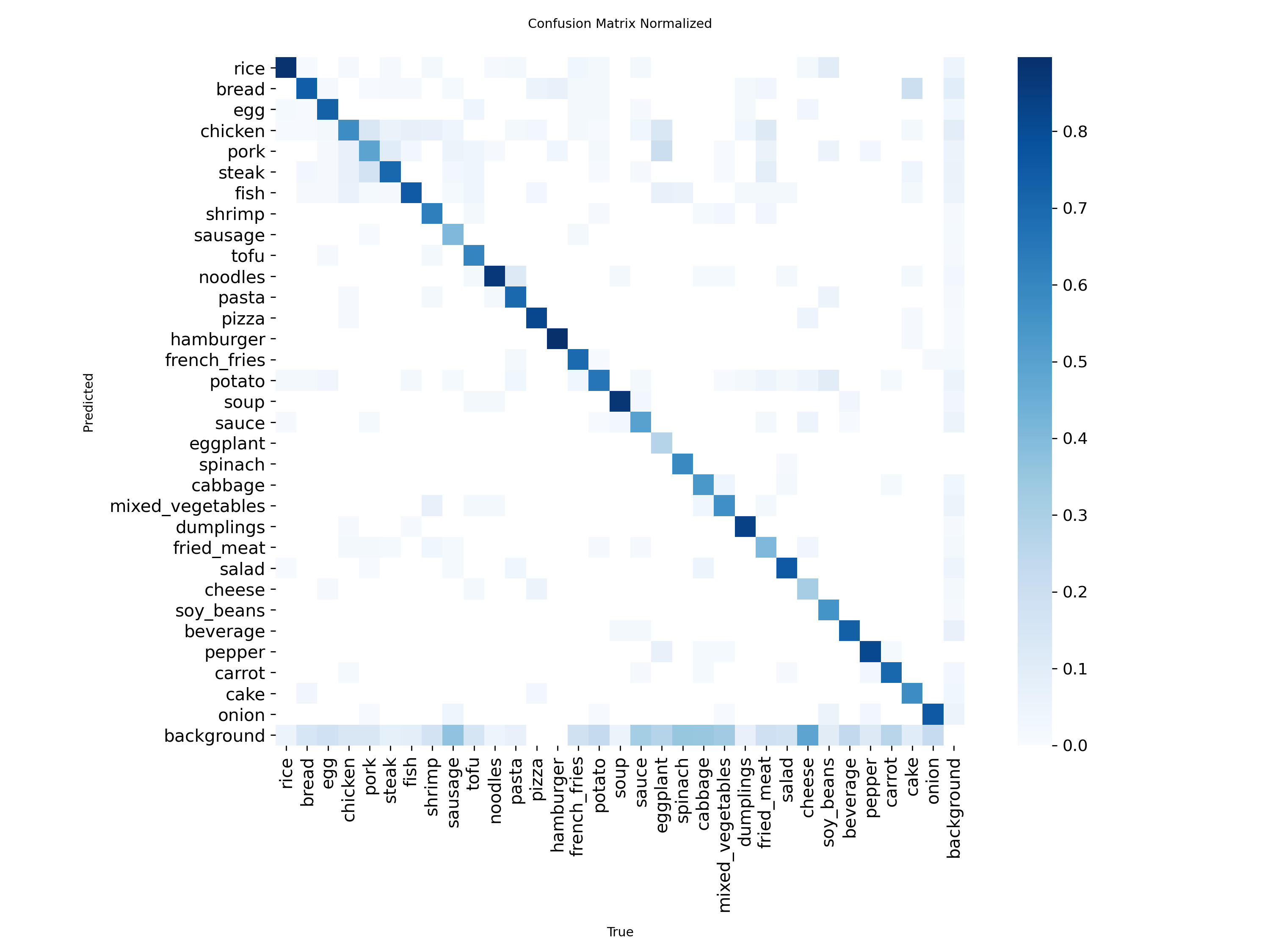
Matrice de confusion normalisée du modèle Fusion
Courbes de Performance (Fusion)
Courbe Précision-Recall (Mask) :
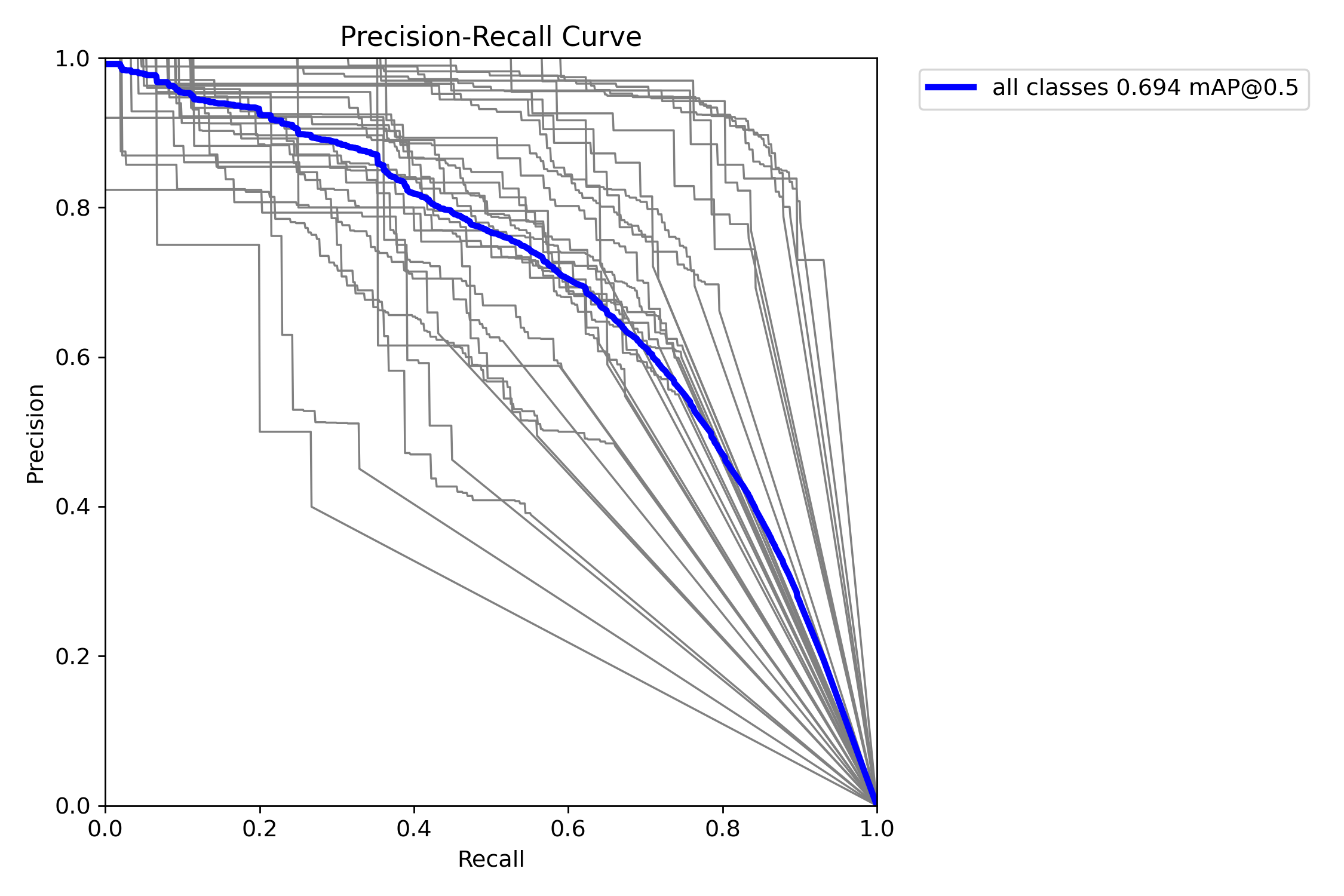
Courbe Précision-Recall pour la segmentation par classe (32 classes)
Courbe F1-Score (Mask) :
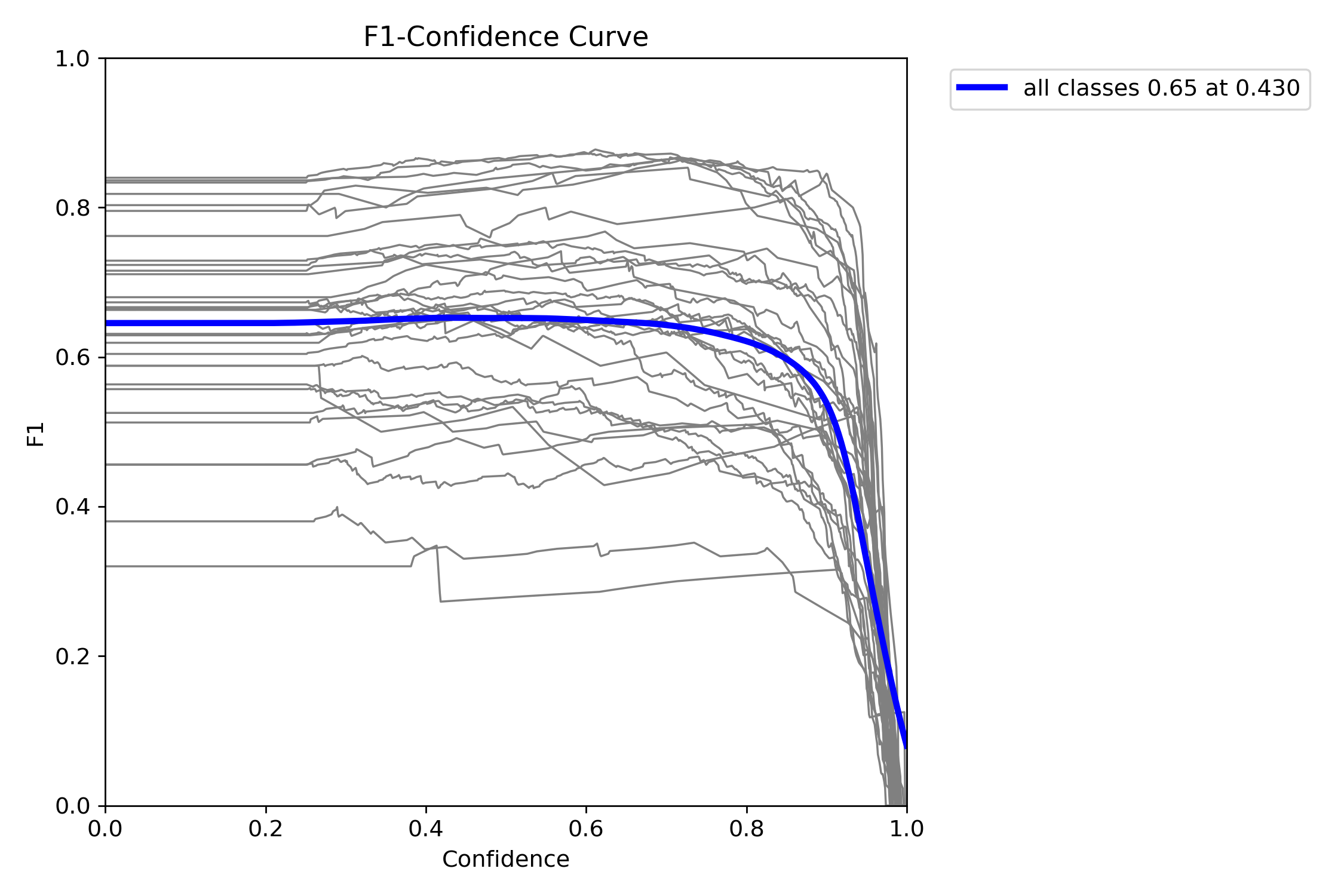
Courbe F1-Score du modèle Fusion en fonction du seuil de confiance
Exemples Visuels de Prédictions (Fusion)
| Ground Truth | Prédictions Fusion |
|---|---|
 | |
 |  |
Comparaison ground truth vs prédictions du modèle Fusion sur les batches de validation
Performance par Classe (YOLOv8m-seg, ancien modèle 12 classes)
Top 3 Classes (mAP50-95 Mask)
| Classe | mAP50 | mAP50-95 | Précision | Recall | Images |
|---|---|---|---|---|---|
| french_bean | 0.951 | 0.883 | 0.928 | 0.894 | 704 |
| onion | 0.845 | 0.754 | 0.812 | 0.798 | 881 |
| rice | 0.823 | 0.751 | 0.789 | 0.801 | 464 |
Analyse : Classes avec formes géométriques simples (french_bean = cylindres, onion = sphères/rondelles) sont mieux segmentées.
Bottom 3 Classes (mAP50-95 Mask)
| Classe | mAP50 | mAP50-95 | Précision | Recall | Images |
|---|---|---|---|---|---|
| pork | 0.412 | 0.168 | 0.523 | 0.389 | 474 |
| chicken_duck | 0.534 | 0.289 | 0.612 | 0.507 | 848 |
| sauce | 0.589 | 0.309 | 0.648 | 0.556 | 818 |
Hypothèses explicatives :
- Texture complexe : La viande (pork, chicken_duck) a une texture hétérogène (fibres, graisses, cuisson variable)
- Formes irrégulières : Sauce liquide sans contours définis
- Confusions inter-classes : Poulet vs porc (similarité visuelle haute)
Distribution des Erreurs (ancien modèle, 12 classes)
Matrice de confusion (YOLOv8m FoodSeg103, test set) :
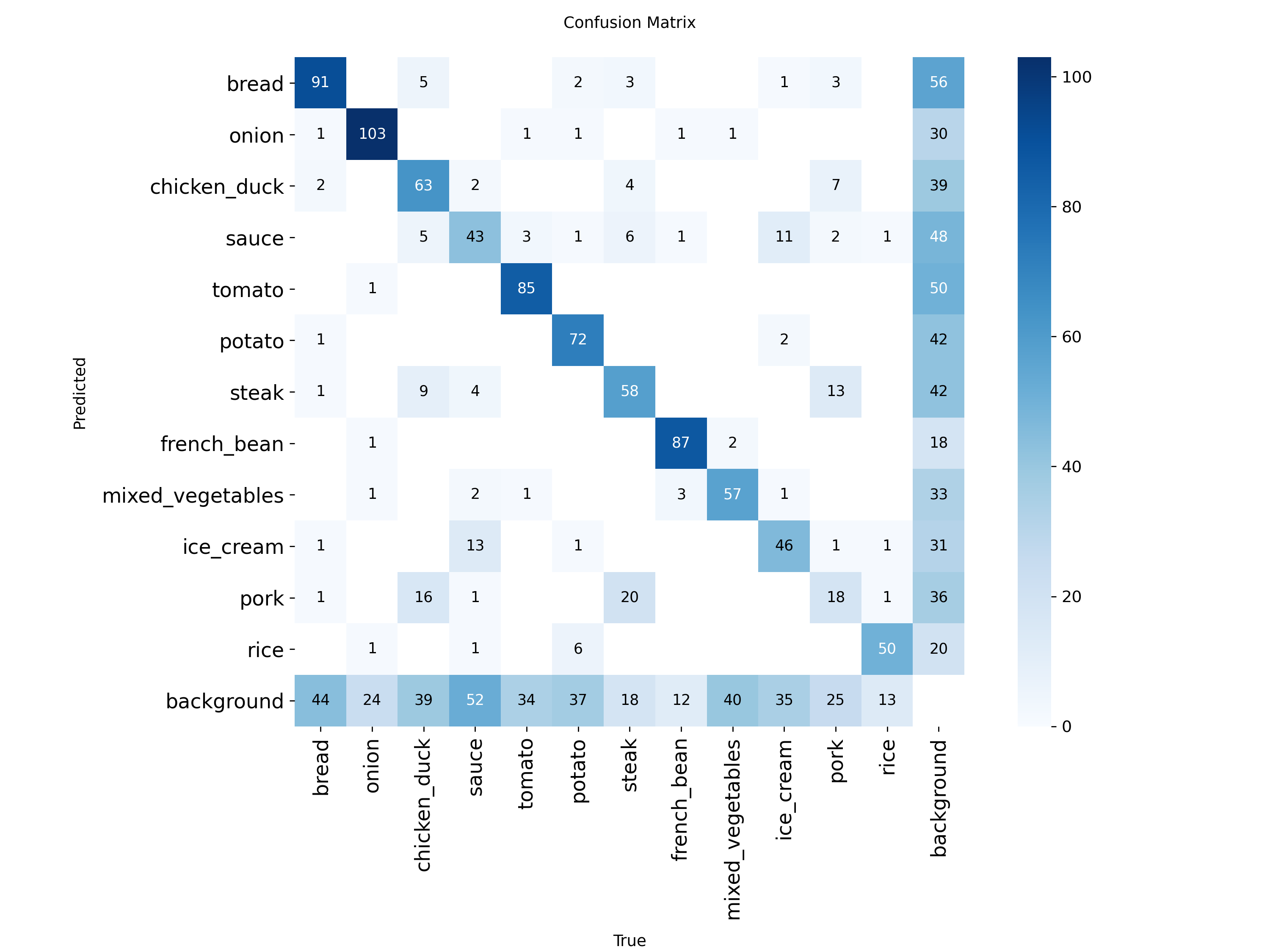
Figure 1 : Matrice de confusion du modèle YOLOv8m-seg sur le test set
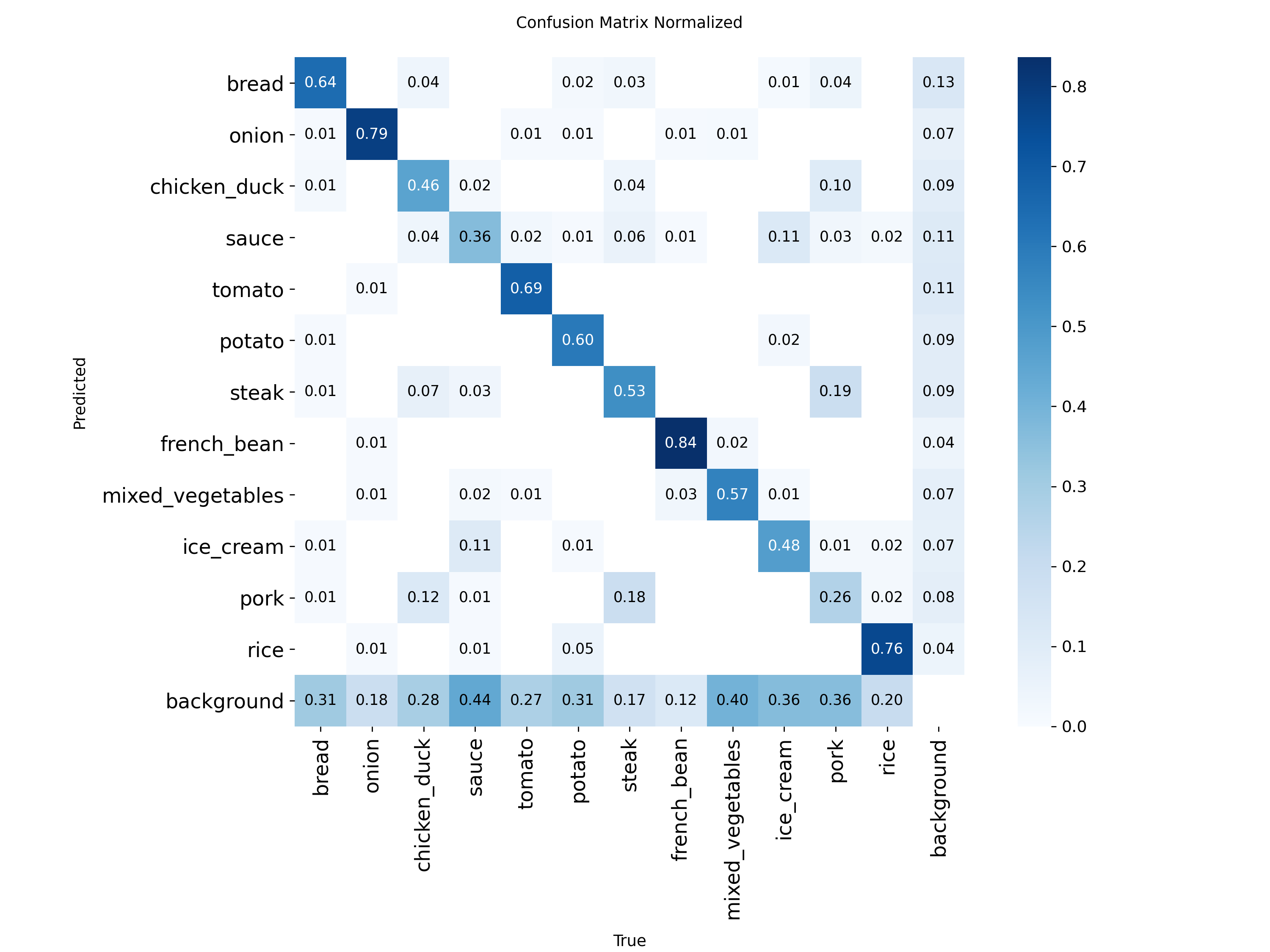
Figure 2 : Matrice de confusion normalisée (pourcentages)
Top confusions identifiées :
Vraie classe vs Prédiction (top confusions)
chicken_duck ─► pork (34 erreurs) # Textures similaires
steak ─► pork (28 erreurs) # Viandes rouges confondues
sauce ─► background (21 erreurs) # Zones liquides non détectées
mixed_vegetables ─► french_bean (18 erreurs) # Légumes verts agrégés
Cause principale : Manque de features discriminantes pour textures fines (résolution 640×640 insuffisante pour détails micro-texturaux).
Courbes d'Apprentissage (ancien modèle, 12 classes)
Évolution des métriques sur 200 époques :
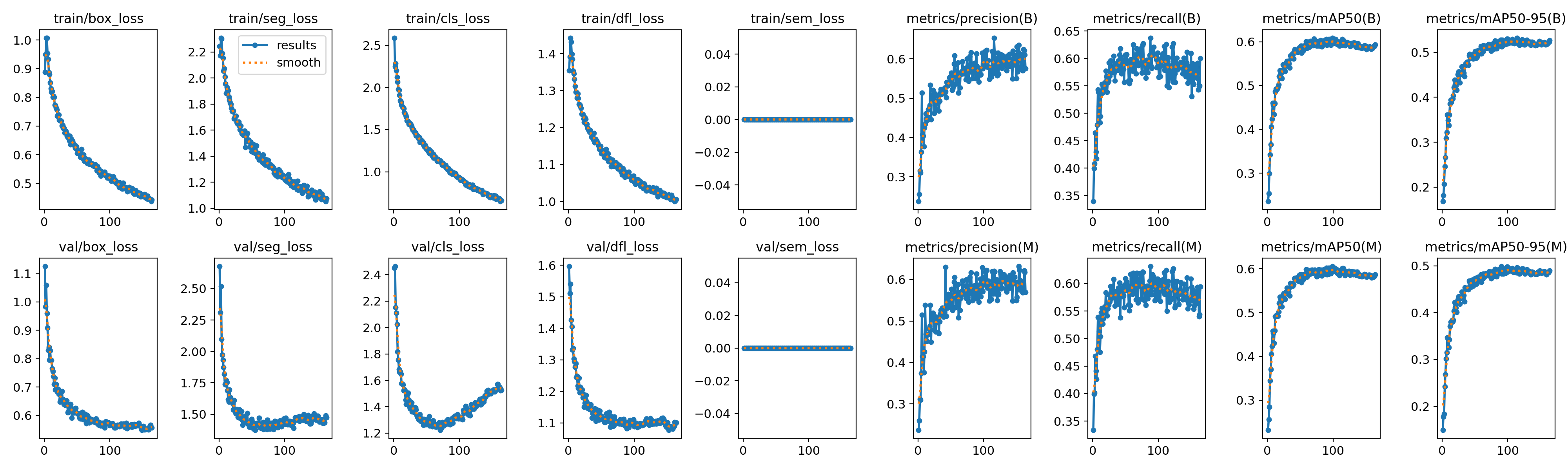
Figure 3 : Évolution des métriques d'entraînement et de validation (losses, mAP, précision, recall) sur 200 époques
Observations clés :
- Convergence rapide (0-50 époques) : Transfer learning efficace depuis COCO
- Plateau (150-200 époques) : Modèle atteint capacité maximale pour ce dataset
- Pas d'overfitting visible : Gap train/val <3% (régularisation augmentations efficace)
- Best epoch: 187 (mAP50=0.6250)
- Early stopping: Non déclenché (patience=50, dégradation max=13 époques)
Courbes de Performance (ancien modèle, Segmentation)
Courbe Précision-Recall (Mask) :
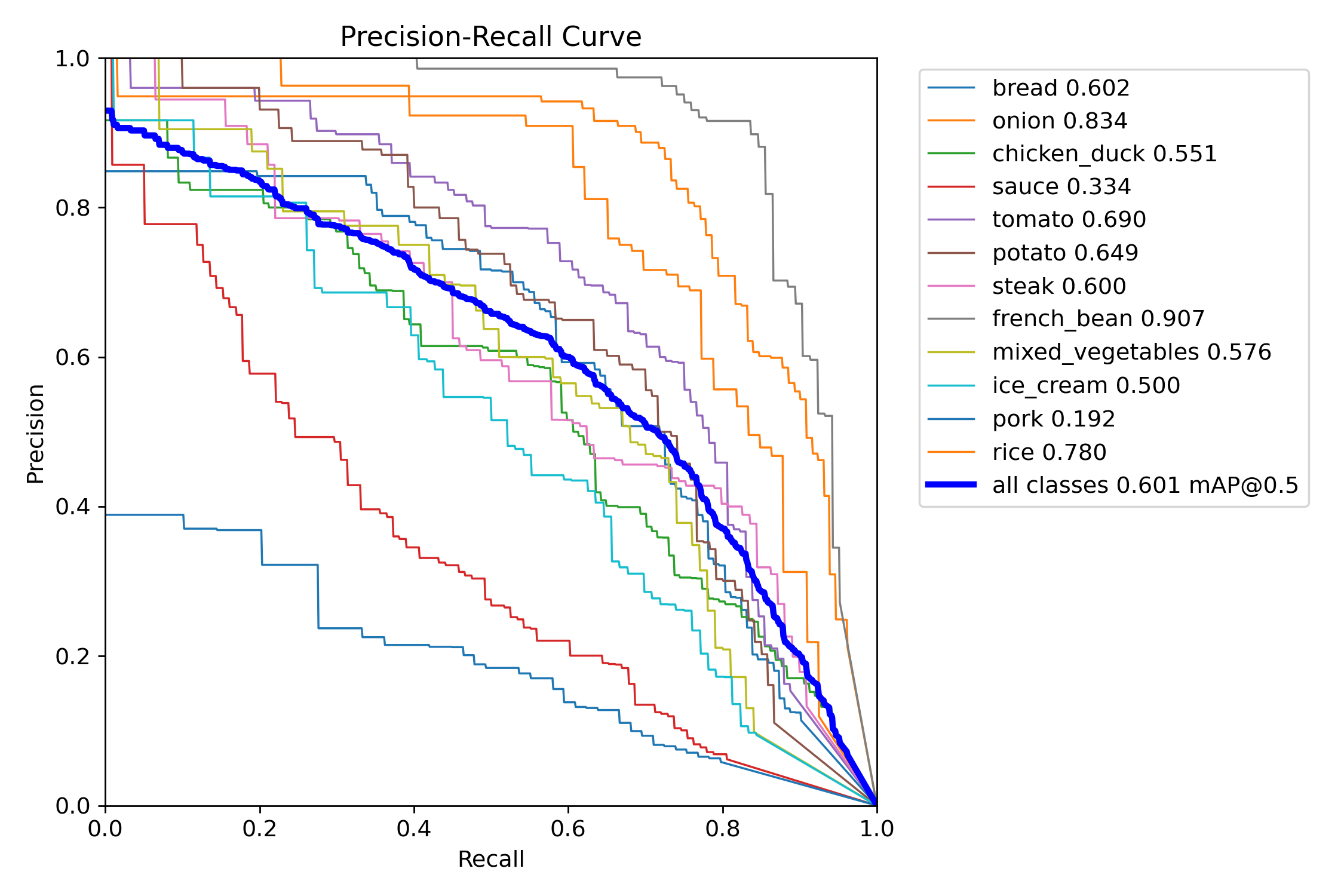
Figure 4 : Courbe Précision-Recall pour la segmentation par classe
Courbe F1-Score (Mask) :
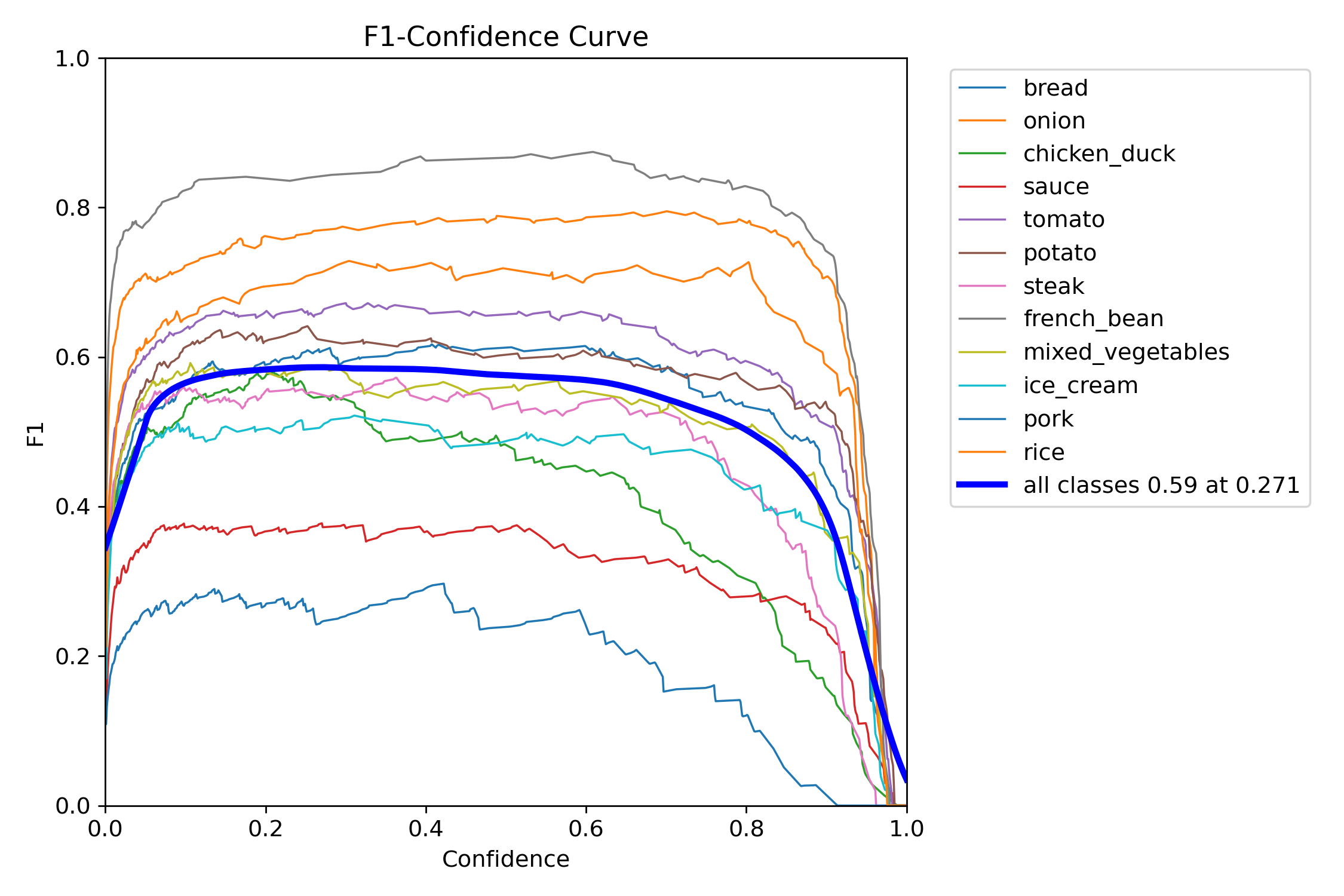
Figure 5 : Courbe F1-Score en fonction du seuil de confiance
Courbes Précision et Recall individuelles :
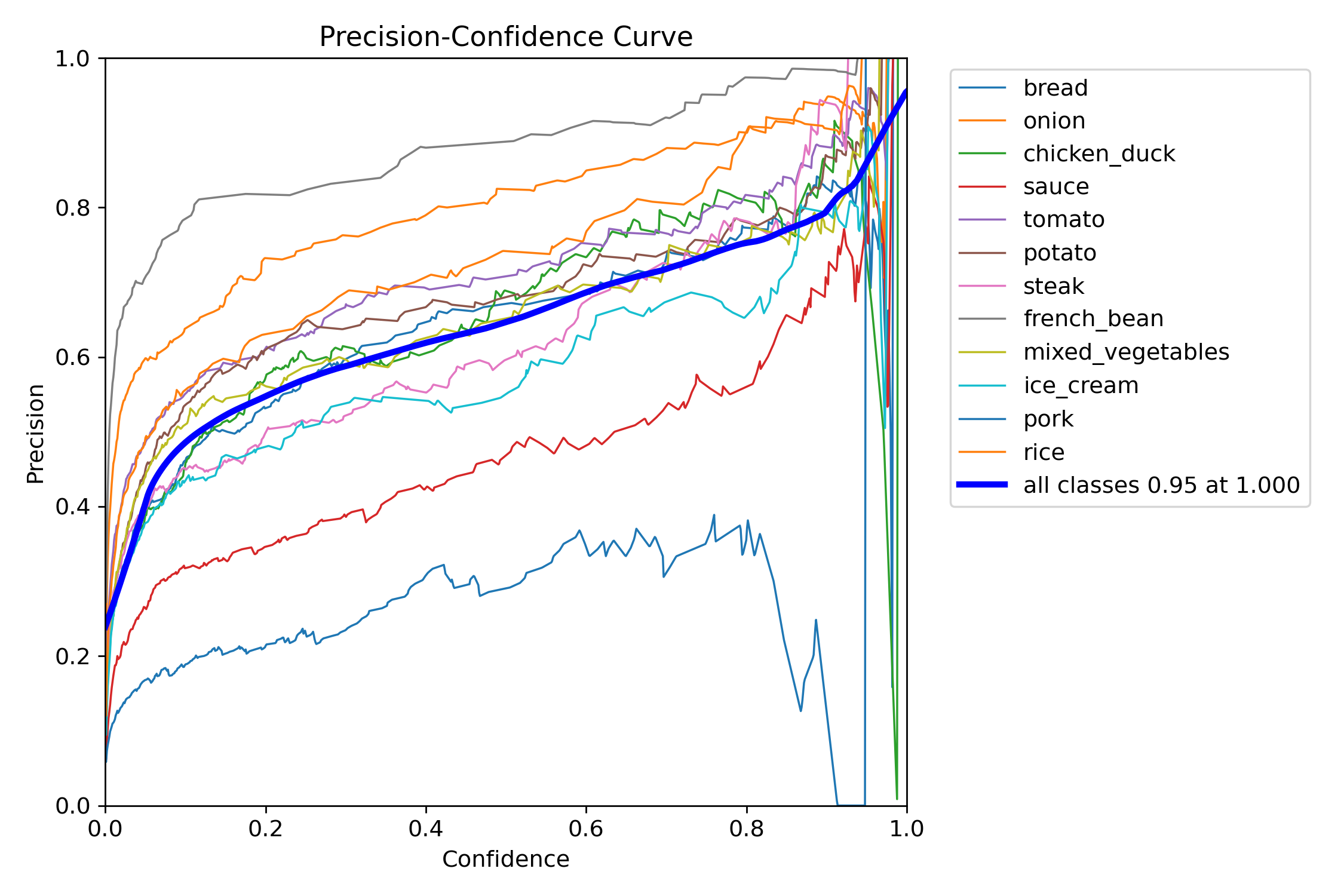
Figure 6 : Courbe de précision par classe
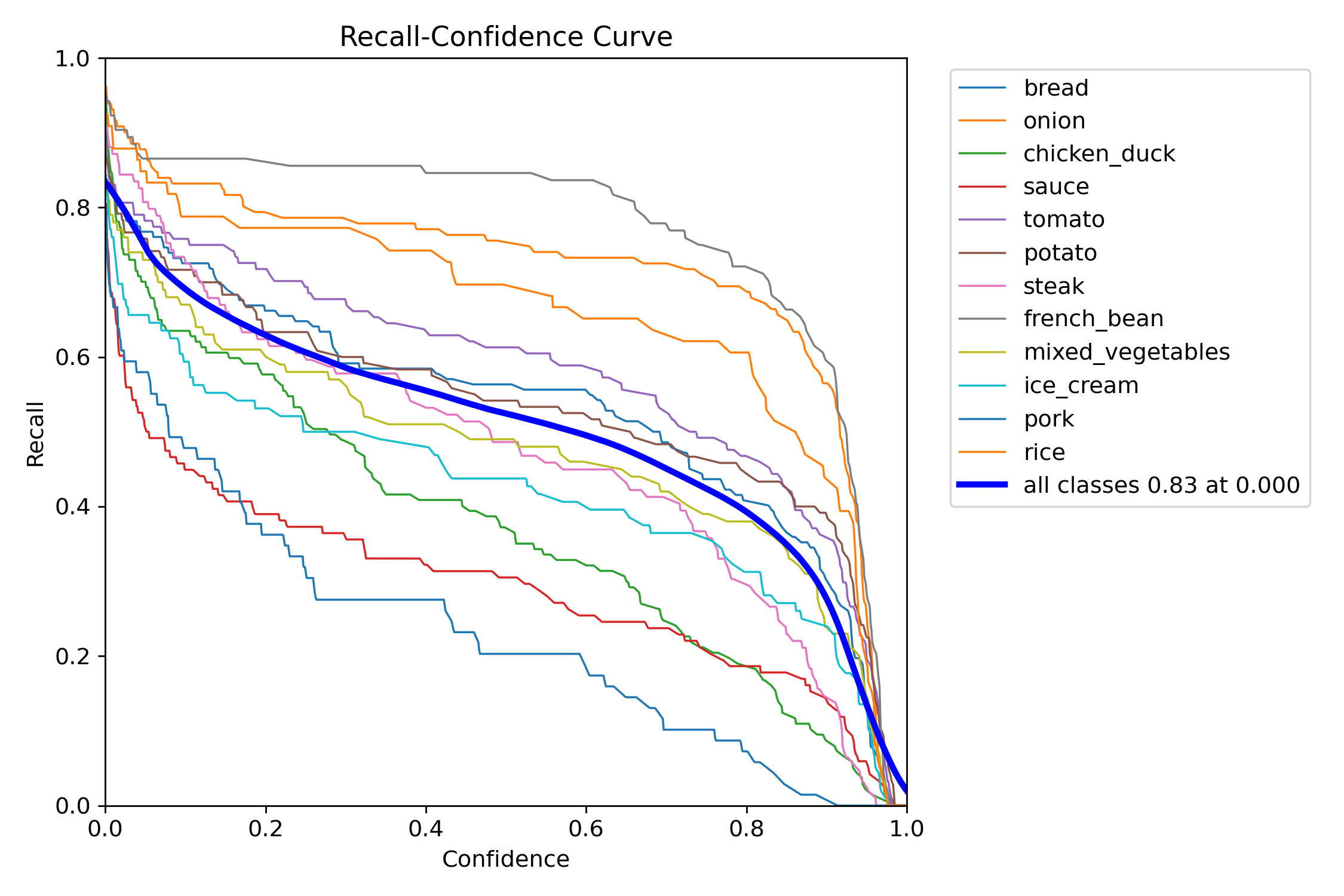
Figure 7 : Courbe de recall par classe
Exemples Visuels de Prédictions (ancien modèle, 12 classes)
Comparaison Labels vs Prédictions (Batch de validation) :

Figure 8 : Ground truth (annotations réelles) - Batch de validation 0
Figure 9 : Prédictions du modèle - Batch de validation 0
Observations visuelles :
- Les masques de segmentation prédits sont généralement bien alignés avec les ground truth
- Certaines classes comme french_bean et onion montrent une excellente qualité de segmentation
- Les classes avec textures complexes (pork, chicken_duck) présentent des contours moins précis
- Le modèle gère bien les scènes multi-objets avec plusieurs aliments par image